Lecture 22 - Distributed Systems
"I think ultimately success is good. Failure not so good...uh..."
- Words of Wisdom from Leonardo DiCaprio in an
interview with Barbara Walters
- Announcements
- Distributed File Systems
- NFS
- Caching and Replication
- AFS
- Parallel File Systems
Last time, we listed and briefly discussed several kinds of
transparency that might be desirable a distributed system. Now we
will look in more detail at network file systems.
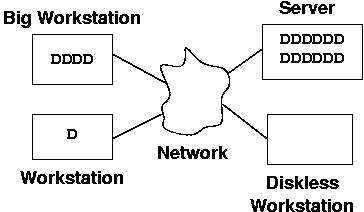
Files on some of these disks may be shared. Perhaps the user files
for all four systems reside on the server. A copy of the OS resides
on the big workstation and the regular workstation, with extra space
on the big workstation used for some special software. Then the
diskless workstation needs everthing, including its OS, from the
server. A distributed file system (DFS) is what manages a
collection of such storage devices.
Terminology:
For a DFS, the client interface most likely includes a set of file
operations, much like those available to access local disks (create,
delete, read, write)
DFS Issues:
Naming Schemes
We share files in our lab using NFS, originally developed by Sun, now
available in many systems.
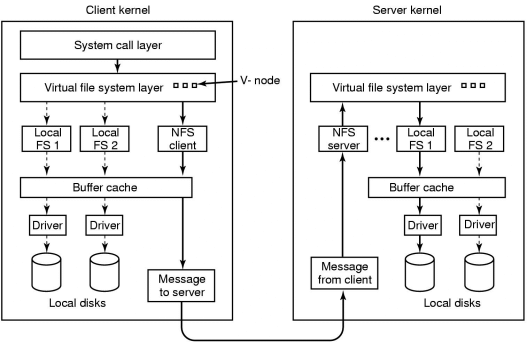
Caching is important - can use the regular buffer cache on the
client, could use client disk space as well. Server automatically
will use its buffer cache for NFS requests as well as any local
requests.
Cache on disk vs. main memory:
Cache Update Policy - mostly the same issues we have seen in other
contexts
Cache Consistency
Need to know if the copy of a disk block in our cache is consistent
with the master copy.
For a stateless system like NFS, the server has no knowledge of which
clients are connected, let alone what is in their cache. There, any
cache consistency protocol must be client-initiated.
Still, it is very difficult to guarantee anything here. Even if the
client can check with the server, it is possible that a dirty block
remains in another client's cache. NFS generally deals with this with
an approach that any modified cache blocks are written back to disk
"reasonably" quickly, usually in a few seconds. So in practice,
problems arise only in systems where there are many concurrent
writes. In these situations, the user processes should do some sort
of file locking to ensure that the cache will not lead to
inconsistencies.
Stateless vs. Stateful File Service
We said that NFS requests are stateless - each request is
self-contained. No open and close operations for the server, as the
file is reopened and gets data at a specific position in the file.
This seems inefficient...
A stateful file server would "remember" what requests have been
made, so a request could be something like "read the next block of
this file"
This can increase performance, by allowing fewer disk accesses on the
server side, using a read-ahead to get blocks into the server's cache
to anticipate upcoming requests.
Failure recovery:
Replication
Similar issues arise when we want to replicate some files to enhance
reliability, efficiency, availability.
The Andrew File System, now known just as AFS, is a
globally distributed file system. Originally from CMU, later supported
by a company called Transarc, which has since become part of IBM. IBM
has released AFS as an open source product.
For more on OpenAFS, see
http://www.openafs.org/
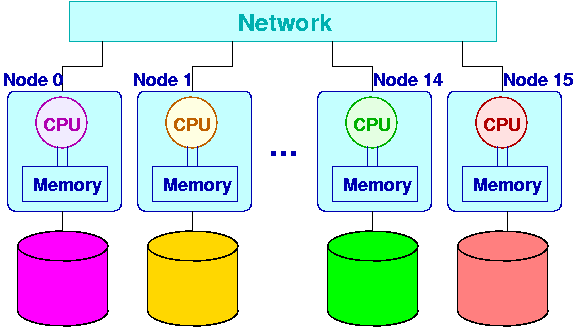
Consider a situation where we have a cluster, where each node has one
or more CPUs, a local memory, and a large local disk.
User processes should be able to run on any node, and have access to a
common file space (home directory, data sets, etc.).
One option is to have all nodes access shared files from an external
file server, or to designate each node in the cluster as having
certain files on its local disk, and the nodes share the files using,
e.g. NFS.
The bullpen cluster uses a combination of these approaches. All nodes
have access to the department's file servers, plus files on the front
end node of the system. Each node has a local disk, and these are
shared (NFS automounted) among the nodes.
Potential problems:
Potential solution: borrow ideas from RAID, and make one big
parallel file system out of the disks attached to cluster nodes!
Just as RAID hides the details of which disk actually stored a given
file, a parallel file system hides which disk and which node stores
a file.
Issues to consider:
Examples of systems that do this kind of thing: