Lecture 21 - Multiprocessing
- Announcements
- Multiprocessing
- Hardware
- Synchronization/Locks
- CPU Scheduling
- Distributed Systems
This week includes a little preview of both electives being offered
next semester: parallel processing, and networks. Here, we'll
concentrate on the OS-related issues that arise when we start putting
multiple processors in a box or when we connect computers over a
network.
Why?
How?
The type of multiprocessing we will be discussing is Multiple-Instruction Multiple-Data (MIMD), where each CPU is running
its own program on its own data. An alternative is Single-Instruction Multiple-Data (SIMD), where all CPUs run the same
program, in fact the same instructions in lockstep, but on different
data. This is often special hardware such as a vector processor.
In a SIMD system, a single instruction might be applied concurrently
on n processors on each element of an n-element array.
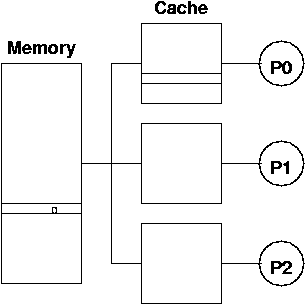
Given a shared-memory architecture, how should the OS manage the CPUs
and the memory?
These kernel locks may seem simple at first, given that in a
single-CPU environment, we know that the kernel rules the world - no
other process is going to do anything without the kernel knowing, as
no other process could be scheduled until the kernel did it. But
with SMP, it is more complex.
Assuming for the moment that we can get kernel locks, we need to be
careful of deadlock. Since a number of CPUs might be holding locks,
one or more of the techniques we discussed earlier in the semester
must be used. It is not good to have a kernel deadlock - the system
will likely grind to a halt. Search the archives on your favorite
open-source kernel's SMP mailing list and you're sure to find examples
of deadlocks.
Way back in September, we talked about process synchronization, and
looked at a number of things, such as Peterson's algorithm and
hardware instructions, to implement synchronization primitives such as
semaphores. We decided that disabling interrupts was a great way to
do this, but in a multiprocessor environment, it just doesn't work.
We can only disable interrupts on one CPU, we can't stop all other
CPUs from continuing their work and introducing unwanted real
concurrency.
Let's look back at our test-and-set implementation of mutual
exclusion:
TestAndSet is atomic in that the process can not be interrupted
until the function completes, but....it is possible for two processes
on two different CPUs to start executing the TestAndSet at the
same time. It is not hard to break the above mutual exclusion in this
case.
For this to work, additional hardware is needed (an extra system bus
line) to ensure that no other CPU can start accessing the bus until
the first to start has completed its operation. Even if it does, we
have a busy wait/spin lock. Here, we could have several processes
tying up several CPUs waiting to acquire a lock. This may sound bad,
but it's even worse - these spin locks will cause cache thrashing, if
we are not careful.
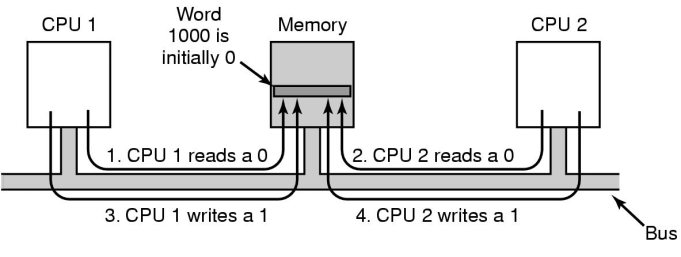
Let's think about this cache thrashing. Consider 3 processes, all
trying to get access to a critical section, using the a test-and-set
instruction on the lock variable shown with a 0 in memory. Assume
that test-and-set really is atomic, using the hardware support
mentioned above.
Consider this sequence of events:
- P0 calls test-and-set on lock
- P1 calls test-and-set on lock
- P2 calls test-and-set on lock
- P1 calls test-and-set on lock
- P2 calls test-and-set on lock
- ... until P0 releases the lock. At that point, P0 will write a
0 to lock and P1 or P2's cache line will be invalidated, and
whoever can grab it next, wins.
This is bad. Not only do we have the undesirable busy wait, but we
are copying chunks of memory over the system bus like crazy.
The text describes three approaches that can help here.
CPU scheduling can be much more complicated when we have multiple CPUs.
Straightforward approach:
This can be a reasonable approach, but it does have some problems:
See also in the text: gang scheduling
Now, we consider distributed systems, where we have a collection of
computers connected by a network. These could be connected by a
private, fast network, in which case we might call it a cluster, or be connected by general-purpose networks, even the
Internet.
The interconnection network itself is not our focus - take the
Networks course. For now, we'll assume that the computers can
communicate with each other.
A networked system allows for
The OS for a distributed system could be:
Network OS is simpler, puts mode burden on the user.
Distributed OS is more complex, but more automated.
Design Issues for A Distributed OS
Transparency - hide distinction between local and remote
resources