Lecture 18 - More File Systems
- Announcements
- File System Interface: Directories
- File System Interface: Disks and Partitions
- File System Implementation
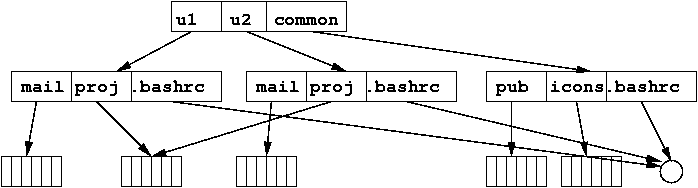
Acyclic-Graph Directories
The tree model does not allow the same file to exist in more than one
directory. We can provide this by making the directory an acyclic
graph.
Two or more directory entries can point to the same subdirectory or
file, but (for now) we restrict it to disallow any directory entry
pointing "back up" the directory structure.
These kinds of directory graphs can be made using links in the
Unix world, shortcuts in the Windows world, or aliases in
the Mac world.
We have multiple names for and multiple paths to the same file.
Unix links can be
This allows sharing of files, but introduces complications - what
happens when the file is removed from one of the directories? If
there may be more references to the file, can we delete it? With
symbolic links, the file just gets deleted and we have a dangling
pointer. With hard links, a reference count is maintained, and the
actual file is only deleted when all references to it are removed.
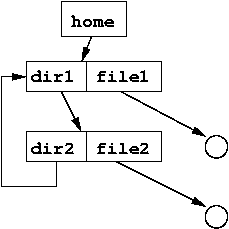
General Graph Directory
What if we allow links back up the chain?
Unix directories have this built in - all directories except the
system's root directory have a special entry .. that indicates
the parent directory, and an entry . that indicates the current
directory.
But they also allow links to be created back "up the chain" of the
directory structures, potentially introducing cycles in the directory
graph.
Need to be careful with command like find that search a
directory and its subdirectories for something. The search is
infinite if cycles are followed. Typically, a program like find
will not follow symlinks.
Problematic cycles can be avoided by allowing "up" links to files,
not directories. Could also run cycle detection every time a new link
is added, if this is a concern. Unix leaves it up to programs to make
sure they treat symlinks appropriately.
BSD 4.3 limits the number of links allowed to be traversed for any
given path name to 8 to avoid undetected cycles. This limit is
actually 32 in the current version of FreeBSD, and 20 for Solaris.
Class demo program: morelinks.c
Directory Implementation
In any case, an individual subdirectory will typically contain a list
of files. How to store this list?
Another consideration: case sensitivity of filenames. Recent Windows, MacOS
filesystems have filenames that remember case, but searches are case
insensitive. Most Unix filesystems are truly case sensitive.
A system may have a number of disks, each with one or more partitions. These are logical subdivisions of the physical disk,
often created to help better organize data on the disk.
A partition is where a filesystem gets created (more on
that soon). Once we have a filesystem, we need to make it accessible
to the world.
In DOS/Windows, this typically involves assigning a letter to each
partition. Then there is a directory hierarchy within each partition.
In Unix, there are no drive letters, everything is considered to be
part of one big hierarchy. One partition forms the root directory
(/) and all others are mounted into the structure it
defines.
The places where partitions get mounted are called mount points,
and are nothing more than regular directories. When a partition is
mounted onto a mount point, the directory is replaced by the contents
of the partition mounted.
When the mount point directory is accessed, the virtual file
system layer of the OS notices that the directory has been used as a
mount point, and sets the current directory to the root of the
partition mounted there.
The partitions mounted can be of any type, but all appear to be part
of the same directory structure. The system delivers requests to the
appropriate partition, and a filesystem-type-specific set of
operations are used to access the actual filesystem.
The list of partitions and their mount points and types are listed in
a file system table file. In FreeBSD, it is located in /etc/fstab; in Solaris, it is /etc/vfstab.
The partitions mounted may be remote as well as local - more on this
next week.
Suppose we have partitioned a disk, and it's time to take those disk
blocks that have been reserved for our partition and create an actual
file system to hold our files. Several issues need to be
considered, such as how we allocate disk blocks within our partitions
to files and directories, how we decide what blocks are available, and
the complexity and efficiency of the choices we might make at this
stage.
Allocation Methods
First, we consider how disk blocks are allocated to files.
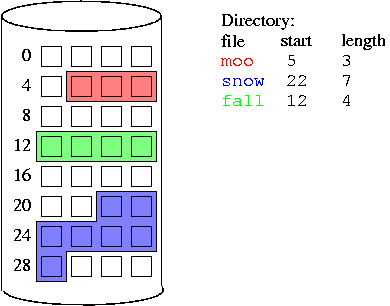
Contiguous Allocation
Each file is allocated a set of contiguous disk blocks
Extents
Extents are analogous to segmentation for memory allocation. Files
are allocated as a collection of extents, which are contiguous
chunks of disk blocks. Each has a starting block and a size.
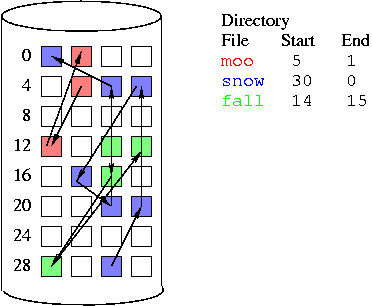
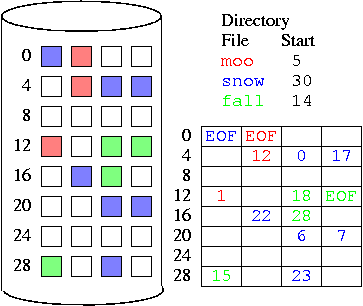
Linked Allocation
Each disk block has a pointer to the next disk block in the file as
well as some file data.
A variation on this is the File Allocation Table (FAT) used by
MS-DOS and pre-NT Windows versions. This gathers the links into one
table.
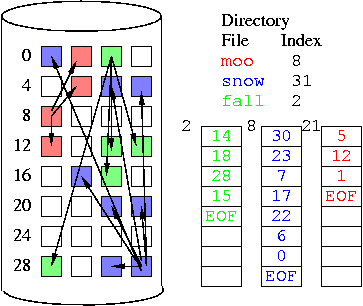
Indexed Allocation
Use disk blocks as index blocks that don't hold file data, but
hold pointers to the disk blocks that hold file data.
Can get around the file size limitation in a few ways:
Unix Inodes
Many Unix filesystems (Berkeley Fast Filesystem, Linux ext2fs, Sun
ufs, ...) take an approach that combines some of the ideas above.
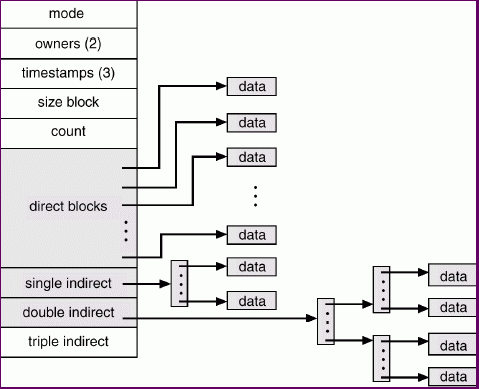
Disk Allocation Considerations
Free Space Management
With any of these methods of allocation, we need some way to keep
track of free disk blocks.
Two main options:
- bit vector - keep a vector, one bit per disk block
- free list - keep a linked list of free blocks
Performance Optimization
Caching is an important optimization for disk accesses.
A disk cache may be located:
See Homework 7 for more about a strategy used by many Unix variants to
use main memory as a disk cache: the buffer cache.
Safety and Recovery
When a disk cache is used, there could be data in memory that has been
"written" by programs, which which has not yet been physically
written to the disk. This can cause problems in the event of a system
crash or power failure.
If the system detects this situation, typically on bootup after such a
failure, a consistency checker is run. In Unix, this is usually
the fsck program, and in Windows, scandisk or some
variant. This checks for and repairs, if possible, inconsistencies in
the filesystem.
Journaling Filesystems
One way to avoid data loss when a filesystem is left in an
inconsistent state is to move to a log-structured or journaling filesystem.