| Bill Gates: | Your Internet ad was brought to my attention, but I can't figure out what, |
| if anything, Compuglobalhypermeganet does, so rather than risk competing | |
| with you, I've decided simply to buy you out. | |
| Homer: | I reluctantly accept your proposal! |
| Bill Gates: | Well everyone always does. Buy 'em out, boys! [Gates' lackeys trash the room.] |
| Homer: | Hey, what the hell's going on! |
| Bill Gates: | Oh, I didn't get rich by writing a lot of checks! [insane laughter] |
Things to consider:
How can we compare the algorithms and approaches?
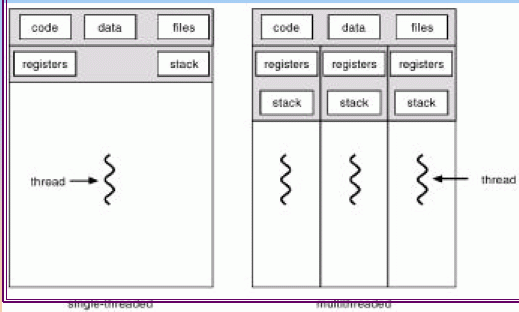
Those of you who have taken or TA'ed for the objectdraw version of CS 134 here know about Java threads. You may have called them ActiveObjects. These gave you the ability to have your programs doing more than one thing at a time. Such a program is called multithreaded.
Threads are a stripped-down form of a process:
Threads can be useful even in single-user multitasking systems:
Sample thread application: NFS server. With heavyweight processes, each request from the network would require a heavyweight process creation. This is expensive since many requests result in frequent, short-duration processes being created and destroyed. With multithreading, one NFS server task can exist, and threads created within the task for each request ("pop-up" threads). There is less overhead, plus if there are multiple CPUs available, threads can be assigned to each for faster performance.
User Threads vs. Kernel Threads
Threads may be implemented within a process (in "user space," also often referred to as "userland") or by the kernel (in "kernel space").
With user threads, the kernel sees only the main process, and the process itself is responsible for the management (creation, activation, switching, destruction) of the threads.
With kernel threads, the kernel takes care of all that. The kernel schedules not just the process, but the thread.
There are significant advantages and disadvantages to each, and Tanenbaum describes these. Some systems provide just one, some systems, such as Solaris, provide both.
One big thing is that with user threads, it is often the case that when a user thread blocks (such as for I/O service), the entire process blocks, even if some other threads could continue. With kernel threads, one thread can block while others continue.
pthreads, POSIX threads We saw how to use fork() to create threads in Unix. There is a POSIX standard interface to create threads.
An online tutorial is available here
A google search for "pthread tutorial" yields many others.
Instead of creating a copy of the process like fork(), create a new thread, and that thread will call a function within the current task.
The basic pthread functions are:
Simplest form:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void * (*start_routine)(void *),
void *arg);
int pthread_join(pthread_t thread, void **status);
void pthread_exit(void *value_ptr);
A pthread "hello, world" program is here.
To compile under Solaris (bullpen), need to link with the pthread library by adding -lpthread to the link line.
To compile under FreeBSD (lab machines), need to pass a special flag -pthread to the compiler and linker to tell it to use the reentrant C library libc_r.a.
We said that threads share more context than processes. To see this, try out this example.
An Independent process is not affected by other running processes.
Cooperating processes may affect each other, hopefully in some controlled way.
Why cooperating processes?
It's hard to find a computer system where processes do not cooperate. Consider the commands you type at the Unix command line. Your shell process and the process that executes your command must cooperate. If you use a pipe to hook up two commands, you have even more process cooperation (See Project 2).
For the processes to cooperate, they must have a way to communicate with each other. Two common methods:
For now, we will consider shared-memory communication. We saw that threads, for example, share their global context, so that is one way to get two processes (threads) to share a variable.
The classic example for studying cooperating processes is the Producer-Consumer problem.

One or more produces processes is "producing" data. This data is stored in a buffer to be "consumed" by one or more consumer processes.
The buffer may be:
Next class, we consider solutions to the bounded buffer problem..