| Brain: | Here we are, Pinky - at the dawn of time! |
| Pinky: | Narf, Brain. Wake me at the noon of time. |
| - Pinky and the Brain | |
We can minimize seek time by minimizing the distance the read/write head has to move in order to service the incoming requests.
Given a sequence of cylinders that must be visited to service a set of pending disk read/write requests, the system can order the requests to minimize seek time.
This may be done by the disk, the hardware controller, or by the operating system.
We will compare algorithms by examining their performance on a given request queue.
Given a disk with 200 cylinders (0-199), suppose we have 8 pending requests:
and that the read/write read is currently at cylinder 53.
First-Come First-Served (FCFS)
We include this analog of FCFS CPU scheduling or FIFO page replacement mainly for comparison purposes.
Requests are serviced in queue order, for a total of 640 cylinders of movement.
Shortest Seek Time First (SSTF)/Closest Cylinder Next
Service the request next that has the shortest movement from the current position.
This is the analog of SJF CPU scheduling and OPT page replacement, but unlike those, it's actually possible, since we do have our actual request queue available to us.
In our example:
The total seek distance is 236 cylinders.
Potential problem: if many requests keep arriving near where the disk head is positioned, distant requests may be starved.
SCAN or Elevator Algorithm
When an elevator is going in one direction, it stops at all the floors where there is a pending request. Then it reverses direction and does the same thing.
With this algorithm, the disk arm does just this. Service requests in one direction, then reverse direction.
In our example, assuming we are "going down" at the start:
236 cylinders again. It is a coincidence that this is the same as SSTF.
Note that the disk arm went all the way to 0, even though there were no requests below 14. This is because this particular algorithm doesn't look ahead, it just moves back and forth from one end to the other.
We can take care of that extra movement down to 0 with ...
LOOK Algorithm
It's the same as SCAN, but the head reverses direction as soon as there are no pending requests in the current direction.
The movement is the same as SCAN, just without that move from 14 to 0 and then up to 65. This reduces the movement to 208 cylinders.
Both SCAN and LOOK can lead to non-uniform waiting times. A request near one end of the disk sometimes needs to wait for two sweeps across the disk, while other times it will be serviced very quickly. Requests near the middle have a more uniform average waiting time.
Circular Algorithms
This problem can be addressed using circular versions of SCAN (C-SCAN) and LOOK (C-LOOK), where when the disk arm gets to the end of the disk, it jumps immediately back to the other end.
Assuming the disk services requests only when "going up", our example using these algorithms are served in order:
With C-SCAN, the head goes all the way to 199 and all the way back to 0, giving total movement of 382. With C-LOOK, we do not need to go up past 183 or down past 14, making the movement total 322.
The penalty of the movement all the way back in the other direction may not be as large as it seems. Think of the mechanics of the situation - starting and stopping the disk arm takes more time than simply sweeping all the way across with just one acceleration and deceleration.
Comparing Disk Scheduling Algorithms
FreeBSD's ufs filesystem (the one we use in the lab) uses an elevator algorithm. Here is the comment at the top of file /sys/ufs/ufs/ufs_disksubr.c:
/* * Seek sort for disks. * * The buf_queue keep two queues, sorted in ascending block order. The first * queue holds those requests which are positioned after the current block * (in the first request); the second, which starts at queue->switch_point, * holds requests which came in after their block number was passed. Thus * we implement a one way scan, retracting after reaching the end of the drive * to the first request on the second queue, at which time it becomes the * first queue. * * A one-way scan is natural because of the way UNIX read-ahead blocks are * allocated. */
We switch focus now to talk about how to organize information on disks.
Hopefully everyone has a good idea what we mean by a file.
Files have a number of attributes:
A number of operations can be performed on files, many of which we have been doing without giving it miuch thought:
File Types
How does a "type" get assigned to a file?
File access may be sequential or direct. Tapes support only sequential access, disk files may support both.
A listing of the files on a disk is a directory.
Both the directory structure and the files reside on the disk.
The directory may store some or all of the file attributes we discussed.
A directory should be able to support a number of common operations:
Directory Organization
There are many ways to organize a directory, with different levels of complexity, flexibility, and efficiency. We will look at several possibilities.
Single-Level Directory
The most simple method is to have one big list of all files on a disk.

This can be used for a simple system. A disk for the C-64 worked like this.
But, it breaks down pretty quickly:
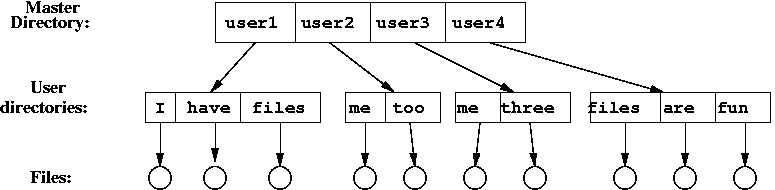
Two-Level Directory
We can create a separate directory for each user:
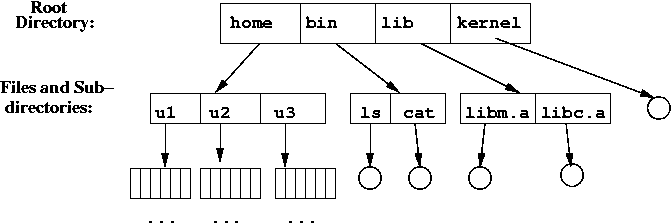
Tree-structured Directory
Something more reasonable and useable:
Acyclic-Graph Directories
The tree model does not allow the same file to exist in more than one directory. We can provide this by making the directory an acyclic graph.
Two or more directory entries can point to the same subdirectory or file, but (for now) we restrict it to disallow any directory entry pointing "back up" the directory structure.
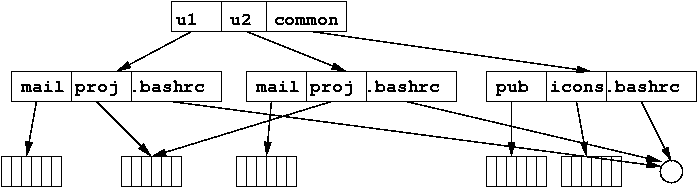
These kinds of directory graphs can be made using links in the Unix world, shortcuts in the Windows world, or aliases in the Mac world.
We have multiple names for and multiple paths to the same file.
More next time...