The self-scheduled midterm exam will be available starting after class on Tuesday. Next Tuesday's class is dedicated to answering your questions. When the questions stop, we move on to new material. I will answer questions up until the end of Tuesday's class.
Last year's project abstracts are available for your viewing.
Note all the deadlines. Start thinking about it now. Or at least once you get past the exam.
Paging
Recall that in a paging scheme, we have a "two memory access problem" if the page table is stored in main memory. Any memory access ends up requiring two. We saw that a fast-lookup hardware cache called a translation look-aside buffer (TLB) can help.
A TLB, being expensive hardware, is significantly smaller than the page table. We are still likely to get a good number of TLB "hits" because of locality of reference - the fact that programs tend to reuse the same pages of logical memory repeatedly before moving on to some other group of pages. This idea will come up a lot for the rest of the semester. But here, it means that if the TLB is large enough to hold (1)/(3) of the page table entries, we will get much, much more than a (1)/(3) hit rate on the TLB.
Multilevel Page Tables
We said earlier that the page table must be kept in main memory. With a large page table, this could end up taking a significant chunk of memory. With a 32-bit logical address space (232) and a 4 KB page size (212), this means there are 220 pages! That's a big page table.
A solution to this is to page the page table! For a two-level paging scheme, we break up our logical address into three chunks: an index into the outer page table p1, a displacement in the outer page table p2 to find the actual frame, and a page offset d.
This means our address translation is now more complex:
Note that we now have 3 memory accesses to do one real memory access! We'll need hardware support here, too.
This can be expanded to 3 or 4 levels.
This approach has been taken with some real systems: VAX/VMS uses 2 levels, Sparc uses 3 levels, and the 68030 uses 4 levels.
If a 64-bit system wanted to use this scheme, it would take about 7 levels to get page tables down to a reasonable size. Not good enough...
Inverted Page Table
Here, we have one entry for each real page of memory, and the page table lists the pid and logical page.
An entry consists of the virtual address of the page stored in that real memory location, with information about the process that owns that page.
This decreases memory needed to store each page table, but increases time needed to search the table when a page reference occurs.
A hash table can limit the search to one or at most a few page-table entries.
The extra memory accesses required for hash-table searches are alleviated by a TLB.
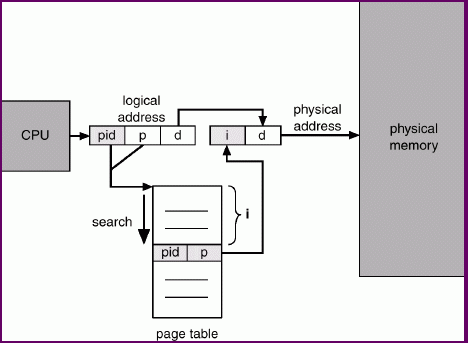
Note that there is one page table shared among all processes. The PID must be part of the logical address.
Memory Protection with Paging
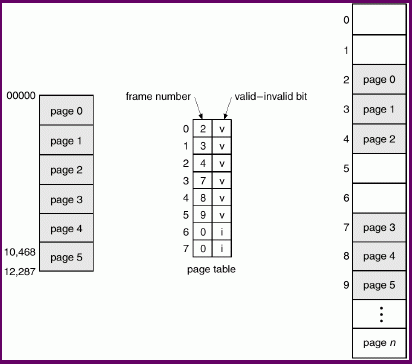
Memory protection with a paging scheme is not as simple as a base/limit pair of registers.
We need to know which process owns each physical memory frame, and ensure that page table lookups for a given process can produce only physical addresses that contain that process' data.
Not all parts of the process' logical address space will actually have a physical frame assigned to them. So page table entries can be given an extra "valid-invalid" bit:
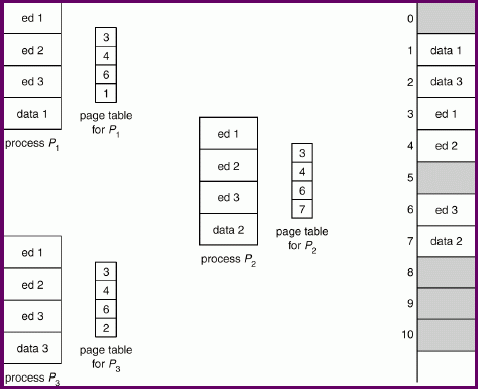
Shared Pages
Processes may be able to share code frames, and processes may wish to share memory.
Complications:
Demand Paging
Recall that virtual memory allows the use of a backing store (a disk) to hold pages of process' logical address space that are not currently in use.
Earlier we talked about moving entire processes between virtual memory and main memory. However, when combined with a paging scheme, we can swap individual pages. This is desirable since relatively small parts of a program text and variables are active at any given time (or possibly, ever).
This can be implemented with the valid-invalid bits of a page table that we saw earlier.
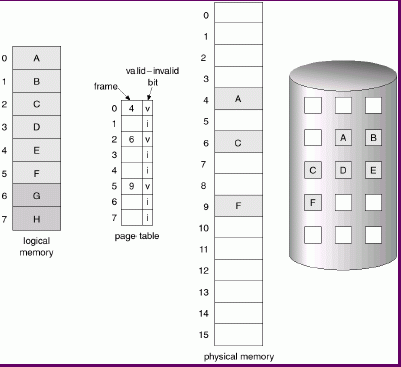
In the figure, logical pages A-F have been allocated by the process, while G and H are part of the logical address space but have not yet been allocated. A, C, and F, have valid page table entries, while the others do not.
If a page lookup hits a page table entry marked as invalid, we need to bring that page in. This is called a page fault.
Page Fault
A page fault causes a trap to the OS.
If the reference is valid, the system must
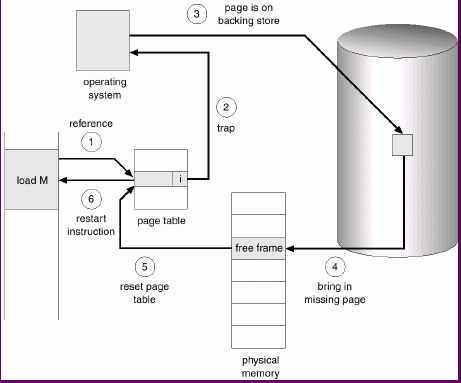
But what happens if there is no free frame? We need to make one!
Page Replacement
To do this, we need to take one of the frames and swap it out - send it back to the disk.
Ideally, we would like to select a frame to remove (a "victim") that is no longer in active use by any process. We will examine some algorithms that attempt to do just this. If the victim is needed again, a page fault will be generated when it is referenced and it will be brought back in.
The percentage of memory accesses that generate a page fault is called the page fault rate. 0.0 <= p <= 1.0 A rate of 0 means there are no page faults, 1 means every reference generates a page fault.
Given a page fault rate p, memory access cost tma, and a page fault overhead tpf, we can compute an effective access time:
tpf includes all costs of page faults, which are time to trap to the system, time to select a victim, time to swap out the page, time to swap in the referenced page, and time to restart the process.
The page being swapped out needs to be written back to disk only if it has been modified. If the page has not been modified since we brought it into main memory, we may be able to skip this step. This, however, depends on the implementation.
For example, suppose a memory access takes 1 µs, trap to the system and selection of a victim takes 50 µs, swapping in or out a page takes 10 ms (= 10000 µs), and restarting the process takes 50 µs. Also, suppose that the page being replaced has been modified 50% of the time, so half of the page faults require both a page write and a page read.
If p=.5, this is pretty horrendous. Our demand paging system has made the average memory access 7500 times slower! So in reality, p must be very small. Fortunately, our friend locality of reference helps us out here again. Real programs will have a low page fault rate, giving reasonable effective access times.
Appropriate selection of the victim can make a big difference here. It may be worthwhile to take more time to select a victim more carefully if it will lower p, and in turn, EAT.
To reduce the page fault rate, we should select victims that will not be used for the longest time into the future.