
The statements at the end of the last class that most systems do not worry about deadlock is a bit misleading. While no systems manage resources with something as elaborate as the Banker's Algorithm, many systems work to avoid deadlock in specific cases, such as with the allocation of file descriptors, process table entries, and memory.
While kernel deadlocks are infrequent in real systems, user process deadlocks are certainly common, which is why we study the 4 conditions.
Memory is one of the major shared resources in any modern system. A program needs access to the CPU, and space in memory for its instructions and data in order to run.
How does the program know how to find the memory location corresponding to variable x? How does the JMP instruction know where to jump to?
Binding to Memory
When does an instruction or a variable get assigned an actual memory address? Three possible times:
This might be used on small systems. Microprocessors might do this. The old DOS .com format programs used this. Programs for things like the Commodore 64 used this.
For example, a BASIC program on the Commodore 64 could include the statement
10 POKE 1024, 1 20 POKE 55296, 6
This puts character 'A' in the upper left position of the screen, then changes its color to blue.
We could also see the current status of joystick 1:
10 JV=PEEK(56320)
Bits correspond to the 4 directions and the fire button status.
A program could also decide to POKE and PEEK values anywhere into memory.
This will not work on a multiprogrammed system, unless each program is compiled to have disjoint memory usage, but the idea lives on in the smaller devices today.
Medium/larger systems may do this. The physical address for a variable or an instruction (branch target) is computed when the program is loaded into memory.
Once the program has been loaded into a section of memory, it cannot move. If it is removed from memory, it must be returned to the original location.
Multiprogramming is possible, and we will consider the issues this brings up for memory management.
This is also used for modern medium and large systems. A program's data and instructions can be moved around in memory at run time.
This allows dynamic loading and/or dynamic linking. Here, a segment of program code is not brought into memory until it is needed.
Logical vs. Physical Address Space
A logical address is one generated by the CPU (your program); and is also referred to as virtual address.
A physical address is the one seen by the memory unit.
These are the same in compile-time and load-time address-binding schemes; they differ in execution-time address-binding scheme.
The Memory-Management Unit (MMU) is a hardware device that maps virtual to physical address. In a simple MMU scheme, the value in the relocation register is added to every address generated by a user process at the time it is sent to memory.
The user program deals with logical addresses; it never sees the real physical addresses.
Memory Protection
If multiple processes are going to be in memory, we need to make sure that processes cannot interfere with each others' memory. Each memory management scheme we consider must provide for some form of memory protection.
Swapping
In a multiprogrammed system, there may not be enough memory to have all processes that are in the system in memory at once. If this is the case, programs must be brought into memory when they are selected to run on the CPU. This is where medium-term scheduling comes in.
Swapping is when a process is moved from main memory to the backing store, then brought back into memory later for continued execution.
The backing store is usually a disk, which does have space to hold memory images for all processes.
Swapping time is dominated by transfer time of this backing store, which is directly proportional to the amount of memory swapped.
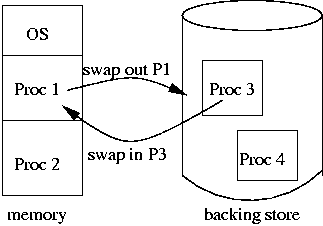
The short-term scheduler can only choose among the processes in memory, and to keep the CPU as busy as possible, we would like a number of processes in memory. Assuming than an entire process must be in memory (not a valid assumption when we add virtual memory), how can we allocate the available memory among the processes?
Contiguous Allocation
If all processes are the same size (not likely!), we could divide up the available memory into chunks of that size, and swap processes in and out of these chunks. In reality, they are different sizes.
For the moment, we will assume that each process may have a different size, but that its size is fixed throughout its lifetime. Processes are allocated chunks of contiguous memory of various sizes.
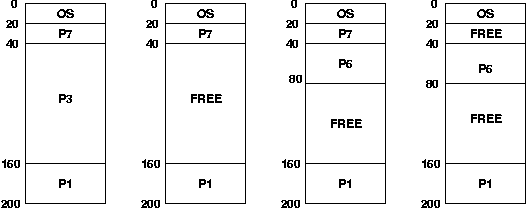
When a process arrives (or is swapped in) it is allocated an available chunk (a "hole") large enough to hold it. The system needs to remember what memory is allocated and what memory is free.
What hardware support is needed to support this relocation?
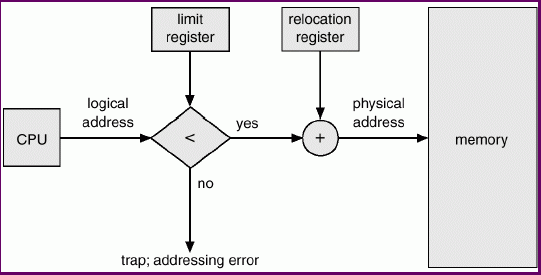
CPU's logical address is first checked for legality (limit register) to ensure that it will be mapped into this process' physical address space, then it is added to an offset (relocation or base register) to get the physical address. If the program is reloaded into a different portion of memory later, the same logical addresses remain valid, but the base register will change.
How do we decide which "hole" to use when a process is added? We may have several available holes to choose from, and it may be advantageous to choose one over another.
Fragmentation
The problem with any of these is that once a number of processes have come and gone, we may have shredded up our memory into a bunch of small holes, each of which alone may be too small to be of much use, but could be significant when considered together. This is known as fragmentation.
External fragmentation can be reduced by compaction - shuffling of allocated memory around to turn the small holes into one big chunk of available memory. This can be done, assuming relocatable code, but it is expensive!
Contiguous allocation will not be sufficient for most real systems.
Paging
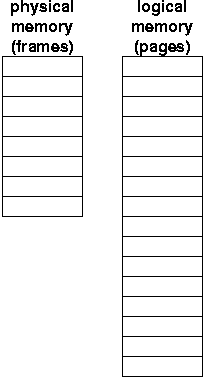
We can do better if we allow a process' logical memory to be noncontiguous in physical memory. An approach that breaks up memory into fixed-size chunks is called paging.
The size of the chunks is called the page size, typically a power of 2 around 4K. We break up both our logical memory and physical memory into chunks of this size. The logical memory chunks are called pages and the physical memory chunks are called frames.
The system keeps track of the free frames of physical memory, and when a program of size n pages is to be loaded, n free frames must be located.
We can create a virtual memory which is larger than our physical memory by extending the idea of process swapping to allow swapping of individual pages. This allows only part of a process to be in memory at a time, and in fact allows programs to access a logical memory that is larger than the entire physical memory of the system.
Fragmentation: we have no external fragmentation, but we do have internal fragmentation.
The contiguous allocation scheme required only a pair of registers, the base/relocation register and the limit register to translate logial addresses to physical addresses and to provide access restrictions. For paging, we need something more complicated. A page table is needed to translate logical to physical addresses.
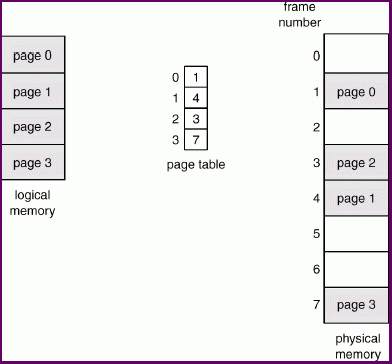
A page table is maintained for each process, and is maintained in main memory.
It is possible that not all of a process' pages are in memory, but we will not consider that just yet.
Logical addresses are broken into:
Disadvantage: every data/instruction access now requires two memory accesses: one for the page table and one for the data/instruction. This is unacceptable! Memory access is slow compared to operations on registers!
The two memory access problem can be solved with hardware support, possibly by using a fast-lookup hardware cache called associative memory or translation look-aside buffers (TLBs)
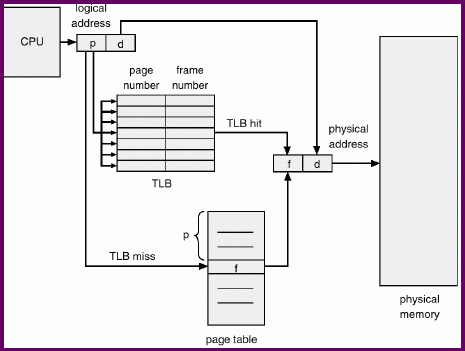
The TLB is an associative memory - a piece of hardware that lets us search all entries for a line whose page number is p. If it's there, we get our frame number f out without a memory access to do a page table lookup. Since this is relatively expensive hardware, it will not be large enough to hold all page table entries, only those we've accessed in the recent past. If we try to access a page that is not in the TLB, we go to the page table and look up the frame number. At this point, the page is moved into the TLB so if we look it up again in the near future, we can avoid the memory access.
Fortunately, even if the TLB is significantly smaller than the page table, we are likely to get a good number of TLB "hits". This is because of locality - the fact that programs tend to reuse the same pages of logical memory repeatedly before moving on to some other group of pages. This idea will come up a lot for the rest of the semester. But here, it means that if the TLB is large enough to hold (1)/(3) of the page table entries, we will get much, much more than a (1)/(3) hit rate on the TLB.