You may work individually or in groups of two or three on this project. Groups must be formed by our class meeting on Tuesday, September 17.
Discrete Event Simulation
Discrete event simulation is a method used to model real world systems that can be decomposed into a series of logical events that happen at specific times. The main restriction on the system is that an event cannot affect the outcome of a prior event. When an event is generated, it is assigned a timestamp, and is stored in an event queue (actually, a priority queue). A logical clock is maintained to represent the current simulation time. At any point in the simulation, the next event to take place is at the head of the event queue. Since nothing of interest can happen between the present simulation time and the timestamp of the event at the head of the event queue, removal of an event for processing allows the logical clock to be incremented to that event's timestamp.
Multiple events may have the same timestamp. This models events that happen concurrently. Even though the events are processed sequentially by the simulator, they occur at the same logical time.
We use this model to simulate a simple operating system. Processes arrive in the system and take turns on the CPU, possibly spending some time waiting for I/O service. Each process remains in the system until its predetermined computational needs are met. There are a small number of events that can occur that will affect the system, and it is these events that drive the simulation.
System Description
You are to design and implement a discrete event simulator to model a round-robin (RR) CPU scheduler. You will then use your simulator to conduct studies of the performance of RR scheduling.
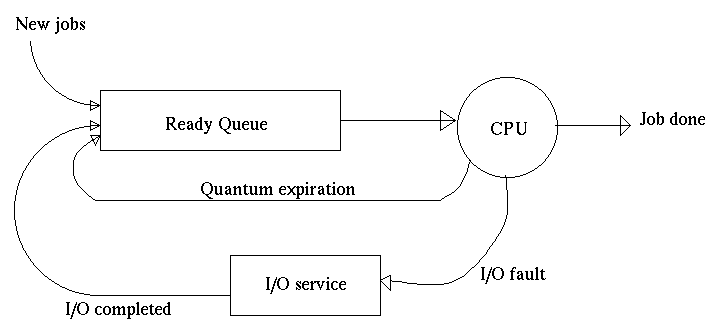
Your program should implement a queueing system, as shown here:
Processes enter the system and wait for their turn on the CPU. They run on the CPU, possibly being pre-empted by the scheduler or for I/O service, until they have spent their entire service time on the CPU, at which point they leave the system.
Context switch time is entered as a parameter by the user and should be accounted for.
User-supplied parameters
Statistics to Gather
Implementation Notes
Submission of simulator source code
Studies to be conducted using the simulator
Conduct two (three if you are in a group with three members) studies of your own choosing using the simulator. These should involve comparisons of statistics such as CPU utilization, turnaround times, and queue lengths, as system parameters are varied. You are encouraged to e-mail me with your ideas to make sure they are appropriate before you go too far.
The most meaningful statistics are collected after the system stabilizes, that is, after the system has been under "load" for a while. The first processes to arrive enter an unloaded system and their behavior may not be typical of long-term trends. Wait until hundreds of processes have entered the system before gathering statistics, or run your simulation long enough that the behavior of these early processes will not have a significant effect on the long-term trends you are studying. Choose parameters that will result in several thousand (or more) processes passing through the system before the simulation ends. Some combinations of parameters produce mostly meaningless results, such as when processes arrive much more quickly than the CPU can process them. Avoid these situations in your studies.
If your simulator is not finished in time to use it for this part of the project, you may generate your results using mine.
What to turn in:
Submission of simulator studies
Honor Code Guidelines
Collaboration within a group is unrestricted. You may ask the instructor or teaching assistant for help. Outside help (classmates, friends, reference manuals) with the programming language (syntax) or computer systems is permissible, but help with the design of your program is restricted to your group members, the instructor, and the teaching assistant. Outside references such as language manuals are permitted. Any other collaboration or consultation is prohibited and will be considered a violation of the Honor Code. If you wish to use any software libraries or outside source code beyond the standard C, C++, or Java libraries, check with me first. If in doubt about anything related to Honor Code, ask now and avoid problems later!