
|
|
Computer Science 211 |
In completing this assignment, you will learn to managing a recursive tree structure and to explore it using sophisticated algorithms; and to explore the notion of a layered abstraction where one class (Lexicon) makes use of other classes (e.g., Iterator, Vector, Set) as part of its internal representation.
First, carefully read all of this handout. You will have questions, so be sure to leave plenty of time to discuss this assignment with me and the TAs. You are not required to submit any design for credit this time, but please do not let that stop you from asking for advice and feedback on your plans before you proceed too far with your implementation.
Before you begin, copy the starter files from the the shared area under labs/lexicon. Here, you will find two fully-functional but inefficient implementations of a lexicon, along with a program that makes use of the lexicon. Familiarize yourself with the interfaces and classes you are given. Large parts of the implementation of the LexiconTester class are fairly complex and interesting but unimportant for our purposes. Focus your attention on its interaction with the Lexicon classes. You will also find three files of example word list inputs: small.txt and small2.txt are small collections of words chosen to test specific situations, while ospd2.txt lists all 127,143 words in the second edition of the Official Scrabble Player's Dictionary.
Note that there are two due dates. Read the requirements carefully to make sure you finish the requirements for part 1 by 9:00 AM, Friday, November 13, 2009, and for the remainder by 8:35 AM, Wednesday, November 18, 2009. The functionality required for each part is specified in the grading table at the end of this document.
Your task is to implement a class that will manage your lexicon. This can be done using something similar to the word lists we saw early in the semester, but we will do something more efficient and sophisticated. Your implementation will need to satisfy the Lexicon interface provided in the starter code. Most of the required methods are straightforward and intuitive. For more information about the usage and purpose of these methods, refer to the comments in Lexicon.java.
Two implementations of the Lexicon interface are provided: LexiconOrderedVector and LexiconOrderedList, which, as you might expect, use an OrderedVector and an OrderedList, respectively, to manage the lexicon. These both work, but are not especially efficient. Note that most of the code for these is the same for either implementation and has been factored out into the LexiconOrderedStructure abstract class.
You are to write a new class that implements the Lexicon interface, but using much more specialized and highly-efficient data structures. Your choice of underlying structures should be informed by the tradeoffs between the speed of word and prefix lookup, amount of memory required to store the data structure, the ease of writing and debugging the code, performance of add/remove, and so on. The implementation we will use is a special kind of tree called a trie (pronounced "try"), designed for just this purpose.
A trie is a letter-tree that efficiently stores strings (in our case, words). A node in a trie represents a letter. A path through the trie traces out a sequence of letters that represent a prefix or word in the lexicon.
Unlike the binary trees we have been considering, each trie node has up to 26 child references (one for each letter of the alphabet). A binary search tree (which we will consider in detail in class soon) eliminates half the words with a left or right turn at each step in a search, but a search in a trie follows the child reference for the next letter, which narrows the search to just those words starting with that letter. For example, from the root, any words that begin with n can be found by following the reference to the n child node. From there, following o leads to just those words that begin with no, and so on recursively. If two words have the same prefix, they share that initial part of their paths. This saves space since there are typically many shared prefixes among words. Each node has a boolean isWord flag which indicates that the path taken from the root to this node represents a word.
Here is a picture of a small trie:
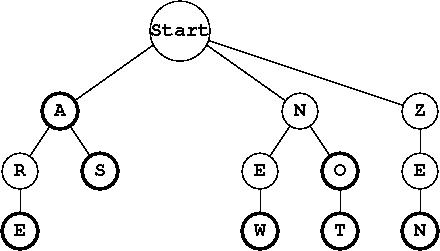
The thick border around a node indicates its isWord flag is true. This trie contains the words: a, are, as, new, no, not, and zen. Strings such as ze or ar are not valid words for this trie because the path for those strings ends at a node where isWord is false. Any path not drawn is assumed to not exist, so strings such as cat or next are not valid because there is no such path in this trie.
Like other trees, a trie is a recursive data structure. All of the children of a given trie node are themselves smaller tries.
You should implement your trie-based lexicon in a class named LexiconTrie. To make use of your LexiconTrie in the LexiconTester, you will need to change the call in LexiconTester to construct a LexiconTrie instead of a LexiconOrderedList.
For each node in the trie, you need a list of references to children nodes. In the sample trie drawn above, the root node has three children, one each for the letters a, n, and z. One possibility for storing the children references is a statically-sized 26-member array of references to nodes, where array[0] is the child for a, array[1] refers to b, ... and array[25] refers to z. When there is no child for a given letter, (such as from z to x in our example) the array entry would be null. This arrangement makes it trivial to find the child for a given letter--you simply access the correct element in the array by letter index.
However, for most nodes within the trie, very few of the 26 references are needed, so using a largely null 26-element array is much too expensive. Better alternatives would be a vector or a linked list of children references. The final choice of a space-efficient design up to you, but you should justify the choice you make in your program comments. Two things you may want to consider: there are at most 26 children, so even an O(n) operation to find a particular child is no big deal, and operations such as iteration require traversing the words in alphabetical order, so keeping the list of children references sorted by letter will be advantageous.
Begin implementing your trie by constructing a LexiconNode class. Note that you will likely want to keep your LexiconNodes in sorted order, so implementing the Comparable interface is likely to be advantageous. After implementing LexiconNode, you should create a constructor in LexiconTrie that creates an empty LexiconTrie to represent an empty word list.
Searching the trie for words and prefixes using containsWord and containsPrefix is a matter of tracing out the path letter by letter. Let's consider a few examples on the sample trie shown previously. To determine if the string new is a word, start at the root node and examine its children to find one pointing to n. Once found, recurse to that child, searching for a match of the remaining part of the string, ew. Find e among its children, follow its reference, and recurse again to match w. Once we arrive at the w node, there are no more letters remaining in the input, so this is the last node. The isWord field of this node is true, indicating that the path to this node is a word contained in the lexicon.
Next, consider a search for ar. The path exists and we can trace our way through all letters, but the isWord field on the last node is false, which indicates that this path is not a word. (It is, however, a prefix of other words in the trie). Searching for nap follows n away from the root, but finds no a child leading from there, so the path for this string does not exist in the trie and it is neither a word nor a prefix in this trie.
All paths through the trie eventually lead to a valid node (a node where isWord has value true). Therefore determining whether a string is a prefix of at least one word in the trie is simply a matter of verifying that the path for the prefix exists.
Adding a new word into the trie with addWord is a matter of tracing out its path starting from the root, as if searching. If any part of the path does not exist, the missing nodes must be added to the trie. Lastly, the isWord flag must be set to true for the final node. In some situations, adding a new word will necessitate adding a new node for each letter, for example, adding the word dot to our sample trie will add three new nodes, one for each letter. On the other hand, adding the word news would only require adding an s child to the end of existing path for new. Adding the word do after dot has been added doesn't require any new nodes at all; it just sets the isWord flag on an existing node to true. Here is the sample trie after those three words have been added:
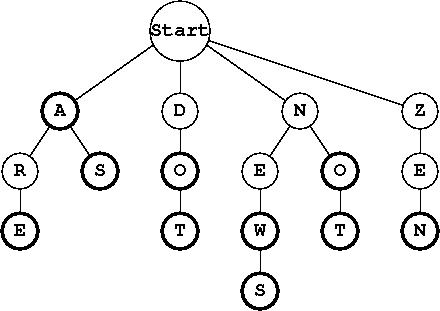
A trie is an unusual data structure in that its performance can improve as it becomes more loaded. Instead of slowing down as its get full, it becomes faster to add words when they can share common prefix nodes with words already in the trie.
The first step to removing a word with removeWord is tracing out its path and turning off the isWord flag on the final node. However, your work is not yet done because you need to remove any part of the word that is now a dead end. All paths in the trie must eventually lead to a word. If the word being removed was the only valid word along this path, the nodes along that path must be deleted from the trie along with the word. For example, if you removed the words zen and not from the trie shown previously, you should have the result below.
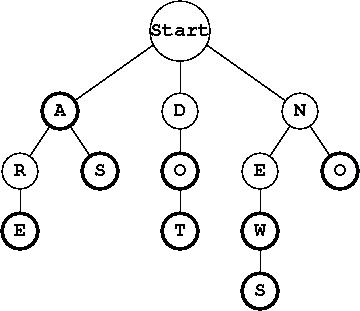
Deleting unneeded nodes is pretty tricky because of the recursive nature of the trie. Think about how we removed the last element of a SinglyLinkedList. We had to maintain a reference to the second to last element to update the references appropriately. The same is true in our trie.
As a general observation, there should never be a leaf node whose isWord field is false. If a node has no children and does not represent a valid word (i.e., isWord is false), then this node is not part of any path to a valid word in the trie and such nodes should be deleted when removing a word. In some cases, removing a word from the trie may not require removing any nodes. For example, if we were to remove the word new from the above trie, it turns off isWord in the w node, but all nodes along that path are still in use for other words.
Important note: when removing a word from the trie, the only nodes that may require removal are nodes on the path to the word that was removed. It would be extremely inefficient to check additional nodes that are not on the path.
There are a few remaining odds and ends to the trie implementation. You need to keep track of the total number of words stored in the trie. Also, you should add support for reading words from a file using a Scanner (you should be able to use the code in LexiconOrderedStructure to accomplish this). Creating an iterator to traverse the trie involves a recursive exploration of all paths through the trie to find all of the contained words. Remember that it is only words (not prefixes) that you want to operate on and that the iterator needs to return the words in alphabetical order.
Next, you will implement the spelling correction features. There are two additional methods in the Lexicon interface, one for suggesting simple corrections and the second for regular expression matching.
Note: Sets are basically just a variant of Vectors that do not allow duplicates. Take a look at Set and SetVector in structure5 for more information.
First consider the suggestCorrections method. Given a (potentially misspelled) target string and a maximum distance, this function gathers the set of words from the lexicon that have a distance to the target string less than or equal to the given maxDistance. We define the distance between two equal-length strings to be the total number of character positions in which the strings differ. For example, place and peace have distance 1, place and plank have distance 2. The returned set contains all words in the lexicon that are the same length as the target string and are within the maximum distance.
For example, consider the original sample trie containing the words a, are, as, new, no, not, and zen. If we were to call suggestCorrections with the following target string and maximum distance, here are the suggested corrections:
|
Target string | Max distance | Suggested corrections |
| ben | 1 | zen |
| nat | 2 | new, not |
Here are a few examples of suggestCorrections run on a lexicon containing all the words in ospd2.txt:
|
Target string | Max distance | Suggested corrections |
| crw | 1 | caw, cow, cry |
| zqwp | 2 | gawp, yawp |
Finding appropriate spelling corrections will require a recursive traversal through the trie gathering those "neighbors" that are close to the target path. You should not find suggestions by examining each word in the lexicon and seeing if it is close enough. Instead, think about how you can generate candidate suggestions by traversing the path of the target string taking small "detours" to the neighbors that are within the maximum distance.
Here you will use recursion to match regular expressions. The matchRegex method takes a regular expression as input and gathers the set of lexicon words that match that regular expression. A regular expression describes a string-matching pattern. Ordinary alphabetic letters within the pattern indicate where a candidate word must exactly match. The pattern may also contain wildcard characters, which specify how and where the candidate word is allowed to vary. Wildcard characters have the following meanings:
For example, consider the original sample trie containing the words a, are, as, new, no, not, and zen. Here are the matches for some sample regular expression:
|
Regular expression | Matching words from lexicon |
| a* | a, are, as |
| a? | a, as |
| *e* | are, new, zen |
| not | not |
| z*abc?*d | |
| *o? | no, not |
Finding the words that match a regular expression will require careful application of your recursive programming skills. You should not find suggestions by examining each word in the lexicon and seeing if it is a match. Instead, think about how to generate matches by traversing the path of the pattern. For non-wildcard characters, it proceeds just as for traversing ordinary words. On wildcard characters, you can "fan out" the search to include all possibilities for that wildcard.
Since we have two due dates, you will likely be making two submissions of the same files. The grading table below lists which functionality is required for part 1 (basics) and which functionality is required for part 2 (advanced). Design, style, and documentation grades will be based only on your part 2 submission.
For each submission, please send the source code for all of your Java files by email to jteresco AT mtholyoke.edu.
This lab assignment is graded out of 50 points. As in all labs, you will be graded on design, documentation, style, and correctness. Be sure to document your program with appropriate comments (use Javadoc!), including your name and a general description at the top of the file, a description of each method with pre and postconditions where appropriate. Also use comments and descriptive variable names to clarify sections of the code which may not be clear to someone trying to understand it.
|
Grading Breakdown | |
| Program design | 7 points |
| Program style | 5 points |
| Program documentation | 8 points |
| Basic (Part 1) Correctness | |
| Basic trie structure | 7 points |
| containsWord | 4 points |
| containsPrefix | 3 points |
| addWord | 5 points |
| numWords | 1 point |
| Advanced (Part 2) Correctness | |
| removeWord | 2 points |
| iterator | 3 points |
| suggestCorrections | 3 points |
| matchRegex | 2 points |
While the advanced (part 2) functionality is more complex to design and implement, it is worth a smaller part of the grade (20%) than the design, style, and documentation (40%) and basic functionality (40%). Therefore, a well-designed and documented submission that is missing some of the advanced functionality will still be eligible for significant partial credit
The program design grade will be based on the design choices you make in the implementation of the LexiconTrie class. The program style grade will be based on code formatting and approriate use of Java naming conventions. The program documentation grade is, of course, based on the comments you provide (including Javadoc and pre and postconditions as appropriate). The program correctness grade is based on how well your program meets the functionality requirements.